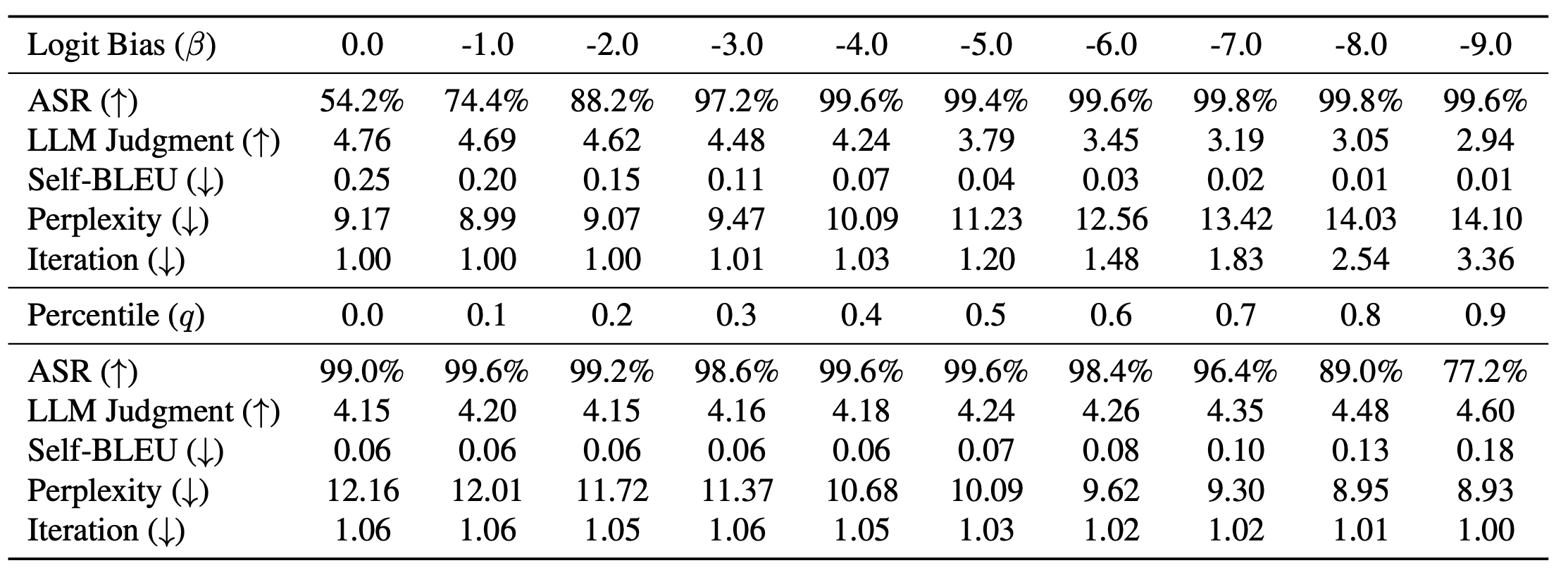
Method
Bias-Inversion Rewriting Attack
The true green list is inaccessible, but the theory says we don't exactly need it — only a small, consistent reduction in green-token sampling. To translate this, BIRA targets likely watermark traces by applying a negative bias during rewriting.
Construct a proxy suppression set $\widehat{\mathcal{G}}$
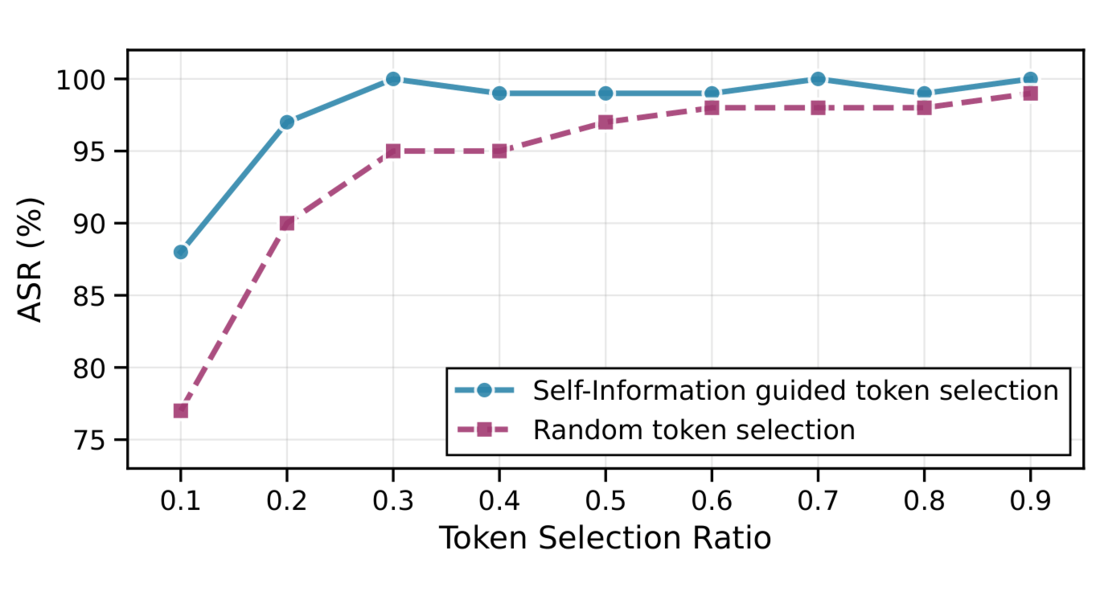
Watermark traces are typically concentrated on high-entropy positions. To suppress these traces, we construct a proxy suppression set $\widehat{\mathcal{G}}$ via token surprisal $I^{(n)}$, keeping tokens above the $q$-th percentile threshold $\eta$:
where $I^{(n)} = -\log P_{\mathcal{M}}\!\big(\hat{y}^{(n)} \mid \hat{y}^{(0:n-1)}\big)$ and $q$ controls the size of the suppression set.
Invert the bias while rewriting
Add a negative logit bias $\beta$ to tokens in $\widehat{\mathcal{G}}$ at every decoding step:
Adapt the bias to avoid degeneration
A strong negative bias $\beta$ can occasionally cause text degeneration. We mitigate this by adapting $\beta$ if the distinct-1-gram ratio $< \rho$ (text is degenerated):
Remark. BIRA replaces SIRA's mask-and-refill step with a controllable negative decoding bias, yielding stronger, more semantics-preserving evasion.